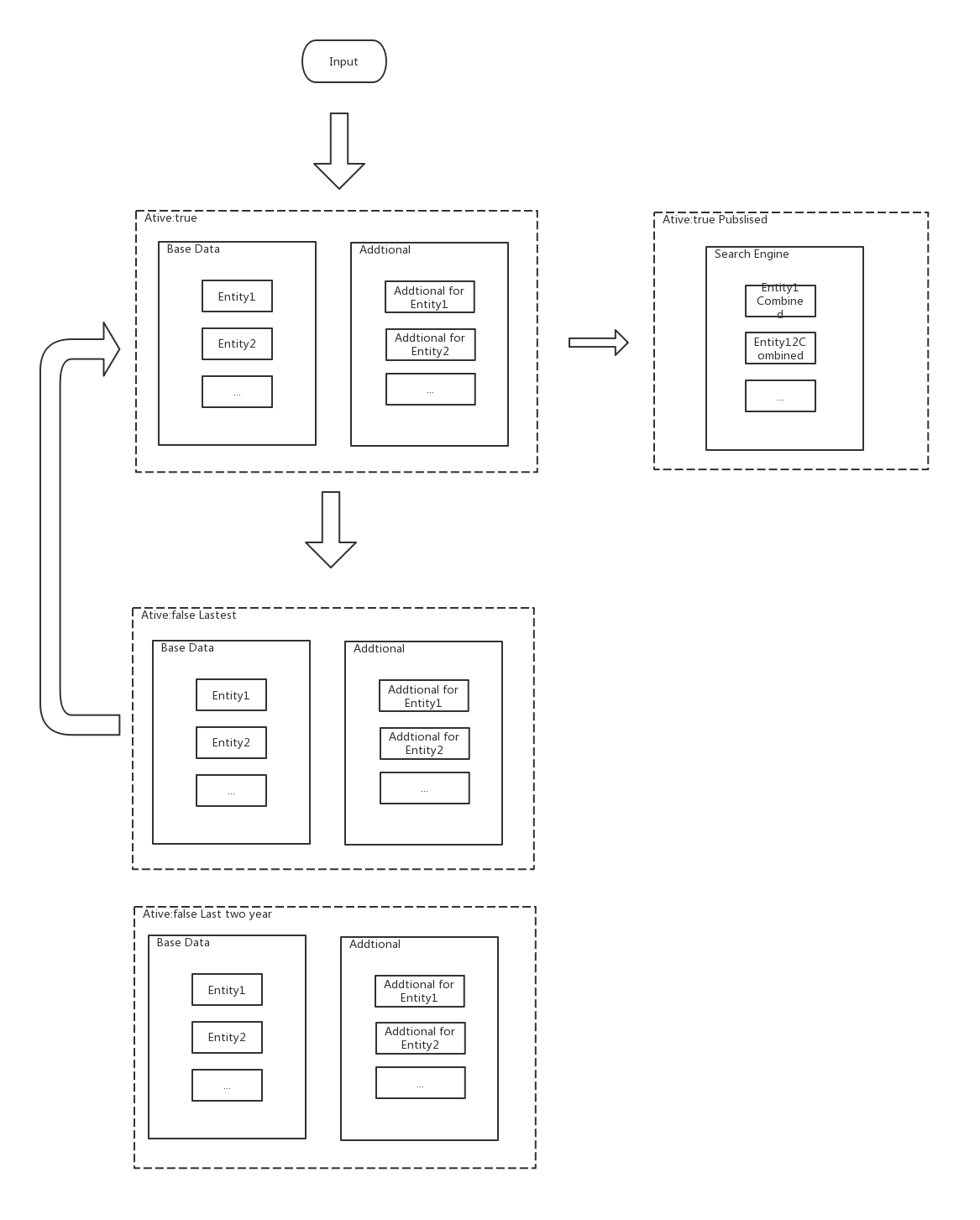
基于关系型数据库的版本管理
概念
业务层对于同一条记录可能编辑多次,为了记录用户修改数据的轨迹,以便追踪活动和还原数据,系统为每次操作生成一个带编号的副本。
分表分库
以 Article 这种 Content Model 为例,同一篇文章可以存在多个活跃的版本(isActive == true),如当前已发布(published),草稿(draft),审核中(pending),和众多的不活跃的历史版本(isActive == false)。大多数时候用户只会使用到 (isActive == true) 的数据,所以进行版本分离存储有助于减少对系统资源的消耗,也能在一定程度上隔离误操作对数据的影响。
设计
“实体标识”与“版本号”
以 {contentModel}Id 作为
实体标识,以 version 作为版本号,({contentModel} + version) 作为唯一键,指向某一实体的某一版本。版本号规则,系统管理员根据业务工作流的环节个数自定义版本格式,即有多少个环节就有多少个以“.”分割的数字。
三个环节 文字小编 0.0.1, 0.0.2 插画小编 0.1.2, 0.2.2 主编 1.2.2 文字小编 1.2.3, 1.2.4, 1.2.5 插画小编 1.3.5, 1.4.5 主编 2.4.5
二个环节 文字小编 0.1, 0.2 主编 1.2 文字小编 1.3, 1.4, 1.5 主编 2.5
一个环节 编辑 1, 2, 3, 4, 5, 6...
优势:各个环节的编辑次数独立记录;信息直观全面;兼容最基础的版本号方案。
关于环节个数设定后是否可以变更,暂未考虑。
频繁更新保护
当同一个用户在n秒内对同一条记录在相同环节进行连续保存时,可以直接更新数据库中的本条记录,减少一些无用版本的产生。
系统管理者应当可以在控制台中开启和关闭“频繁更新保护”功能,以及设置保护的时间间隔n。
CURD 策略
假设在简历编辑页面中包含了 Titan 的基本信息,多个 Experiences ,每个 Experience 都要填写一个 Company ,那么在 UX 的设计上需要遵守指定规则,即每个 Content Model 的字段单独保存,以 LinkedIn 的个人简历页面设计为参考。特别注意,一种 Content Model 的每个实体都要单独保存,批量保存会产生很繁琐的“批量条目修改前后内容对比”的逻辑。
“当前数据表” - 存储活跃版本数据的数据表
“历史数据表” - 存储历史版本数据的数据表
---简历原始版本1.0---
Titans
id = 100001, titanId = 101, version = 1.0, status = 'published', name = 'Cook'
Experiences
id = 200001, experienceId = 201, version = 1.0, status = 'published', titanId = 101, titianVersions = [1.0], companyId = 301, companyVersions = [1.0]
id = 200002, experienceId = 202, version = 1.0, status = 'published', titanId = 101, titianVersions = [1.0], companyId = 302, companyVersions = [1.0]
Companies
id = 300001, companyId = 301, version = 1.0, status = 'published', name = 'Freescale', industries = ['Hardware']
id = 300002, companyId = 302, version = 1.0, status = 'published', name = 'Google', industries = ['Internet', 'Software']
新增操作 - 打开 titanId = 101 的简历,新增一条 Experience 并保存。
技术实现步骤:
1. 在当前数据表中新增一条
`id = 200003, experienceId = 203, version = 1.0, status = 'published', titanId = 101, titianVersions = [1.0], companyId = 303, companyVersions = [1.0]`
更新操作 - 修改个人基本信息,将 name 改为 Cookie。
技术实现步骤:
1. 将该条记录 copy 至历史数据表
`id = 111001, titanId = 101, version = 1.0, status = 'published', name = 'Cook'`
2. 将该条记录在当前数据表中删除
3. 在当前数据表中新增一条
`id = 110001, titanId = 101, version = 1.1, status = 'published', name = 'Cookie'`
4. 向与 titanId = 101 version = 1.1 关联的 Experiences 发送关联信息
`id = 200001, experienceId = 201, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 301, companyVersions = [1.0]`
`id = 200002, experienceId = 202, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 302, companyVersions = [1.0]`
`id = 200003, experienceId = 203, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 303, companyVersions = [1.0]`
删除操作 - 公司因经营不善而倒闭,将这个公司从公司列表中删除。
技术实现步骤:
1. 将该条记录 copy 至历史数据表
`id = 333001, companyId = 301, version = 1.0, status = 'published', name = 'Freescale', industries = ['Hardware']`
2. 将该条记录在当前数据表中删除;
3. 在当前数据表中新增一条 status = 'deleted' 的条目,包括 version 在内的所有字段均保持原值
`id = 330001, companyId = 301, version = 1.1, status = 'deleted', name = 'Freescale', industries = ['Hardware']`
4. 向与 companyId = 301 version = 1.1 关联的 Experiences 发送关联信息
`id = 200001, experienceId = 201, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 301, companyVersions = [1.0, 1.1]`
`id = 200002, experienceId = 202, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 302, companyVersions = [1.0, 1.1]`
`id = 200003, experienceId = 203, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 303, companyVersions = [1.0, 1.1]`
如果这条公司记录是测试数据,或者因其他原因需要硬删除:
1. 将所有 companyId = 301 的公司条目在当前数据库和历史数据库中均删除;
2. 将所有关联了 companyId = 301 的其他类型实体的 companyId 字段置为 NULL;
查询操作 - 执行以上系列操作后再次查看简历内容(假设该版简历为1.1版)
技术实现步骤:
1. 读取当前 Titans 数据表中 titanId = 101 的条目;
`id = 110001, titanId = 101, version = 1.1, status = 'published', name = 'Cookie'`
2. 读取当前 Experiences 数据表中 titanId = 101 的条目
`id = 200001, experienceId = 201, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 301, companyVersions = [1.0, 1.1]`
`id = 200002, experienceId = 202, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 302, companyVersions = [1.0, 1.1]`
`id = 200003, experienceId = 203, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 303, companyVersions = [1.0, 1.1]`
3. 读取当前 Companies 数据表中 companyId = [301, 302, 303] 的条目
`id = 330001, companyId = 301, version = 1.1, status = 'deleted', name = 'Freescale', industries = ['Hardware']`
`id = 300002, companyId = 302, version = 1.0, status = 'published', name = 'Google', industries = ['Internet', 'Software']`
`id = 300003, companyId = 303, version = 1.0, status = 'published', name = 'IBM', industries = ['IT Services']`
查看历史记录操作 - 查看1.0版简历
技术实现步骤:
1. 读取 PastVersionTitans 数据表中 titanId = 101 version = 1.0 的条目
`id = 111001, titanId = 101, version = 1.0, status = 'published', name = 'Cook'`
2. 读取 PastVersionExperiences 或 Experiences 数据表中 titanId = 101, titanVersion = 1.0 的条目(xxxVersions数组的产生是由于在此处遇到了问题,显然相关联的工作经历位于当前 Experiences 表中,任何含有外键的表,必须要有外键对应的版本号,并外键对应的版本号应该是一个数组,即 titanVersions = [1.0, 1.1])
`id = 200001, experienceId = 201, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 301, companyVersions = [1.0, 1.1]`
`id = 200002, experienceId = 202, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 302, companyVersions = [1.0, 1.1]`
`id = 200003, experienceId = 203, version = 1.0, status = 'published', titanId = 101, titanVersions = [1.0, 1.1], companyId = 303, companyVersions = [1.0, 1.1]`
3. 读取 PastVersionCompanies 或 Companies 数据表中 companyId = [301, 302, 303] 的条目,但是不知道相应的版本是什么,进行不下去了。
活动数据与历史数据分离和历史数据切割